

![従来システムトレードと、機械学習を用いたシステムトレードの比較について[藍崎@システムトレーダー]](https://forex-online.jp/wp-content/uploads/2025/01/vol14-aisaki-system-trader-1.png)

硬骨の研究者という雰囲気を醸し出す藍崎さんに、自由自在に語っていただく企画です。
今回は、従来システムトレードと、機械学習を用いたシステムトレードの比較について、縦横無尽に解説していただきます。

藍崎@システムトレーダー氏プロフィール
クオンツから定量分析を学んで生き残りたい個人トレーダー。システムトレードをする傍ら、MT5でEA開発も行う。よく使うのはMQL5、Python、R、Excel VBA。

機械学習を用いたトレード戦略
機械学習や人工知能(AI)というと、人間の学習能力や意思決定などをコンピューター上で実現させているようなイメージで、機械学習から出力された予測結果に基づくトレードに懐疑的な印象を持っている人も多いのではないでしょうか。「ベイズ推論による機械学習入門(※1)」では機械学習を次のように定義しています。
〈引用〉機械学習とは、データに潜む規則や構造を抽出することにより、未知の現象に対する予測やそれに基づく判断を行うための計算技術の総称である。
つまり、機械学習は「人間っぽさ」を追求した技術ではなくて「データのノイズに隠れた意味のある規則や構造」を抽出するための技術です。機械学習を使ったトレード戦略はこの技術を、相場のエッジを見つけるために役立てようとしています。
従来のシステムトレード戦略の問題点
システムトレードにもさまざまな設計がありますが、ここでは「あらかじめ決めたルールに基づいてトレードを行う戦略」を従来の戦略として考えます。開発者は取引ルールを決め、プログラムを作成し、バックテストにてその戦略の優位性の有無を検証します。
開発の例として、EAでよく利用されている仲値戦略で考えてみましょう。開発者は事前にゴト日(5と10の付く日)の仲値前にドルが買われやすい傾向があるという情報を知り、これを元に戦略を立てます。ゴト日の仲値を狙って9:55にドル円のロングポジションを決済するとして、何時何分からポジションを持つのかを最適化できるように設計します。最適化するパラメーターを設定しているため、ウォークフォワード法などを用いてアウトオブサンプルテストを実行できますが、
●開発者はゴト日の仲値前にドルが買われやすい傾向が過去にあったことをバックテスト前から知っている
●システムがゴト日の仲値前にドル円をロングすることが決まっている
という検証となっており、「ゴト日の仲値前にドルが買われやすい傾向」が過去相場の都合のいい後付け解釈になってしまっているのではないかという懸念があります。このように過去にどんな値動きの傾向があったかを知っている開発者が、あらかじめ決めたルールに基づいてトレードを行う戦略を作っているという行為が、アウトオブサンプルテストの意味を一部なくしていると考えられます。
一方で機械学習は戦略のロジックを開発者があらかじめ決めるということは行いません。機械学習はデータの傾向や構造を抽出する技術ですので、インサンプルデータの傾向や構造を抽出してアウトオブサンプルの予測可能性を評価します。過去データの傾向を知っている開発者がロジックを決めるのではなく、アウトオブサンプルを全く知らない機械学習モデルが、システムの挙動を決定するのです。
高次元データの傾向抽出
従来の戦略では多くの変数(テクニカル指標、ファンダメンタルズ指標、日時情報など)を取り入れた複雑なシステムというのは、オーバーフィッティングを招く恐れがあるという理由で敬遠されてきました。一方で機械学習は、多くの変数(高次元データ)からノイズではない意味のある傾向を抽出するための技術が多くあるため、従来の戦略では発見が困難なエッジを見つけられる可能性があります。このような技術や手法の概要をいくつか簡単に紹介します。
特徴量選択
特徴量とは戦略に必要な複数の変数を機械学習モデルがインプットできる状態に加工したデータのことです。オーバーフィッティングを避けるためにできる単純なアイデアとして、用意した特徴量の中からノイズ成分が高い特徴量をインサンプル内で削除してからアウトオブサンプルで評価する方法があります。
正則化
正則化は、モデルに罰則項を与え、複雑になり過ぎることを抑制する仕組みです。代表的なものにリッジ回帰とラッソ回帰があります。
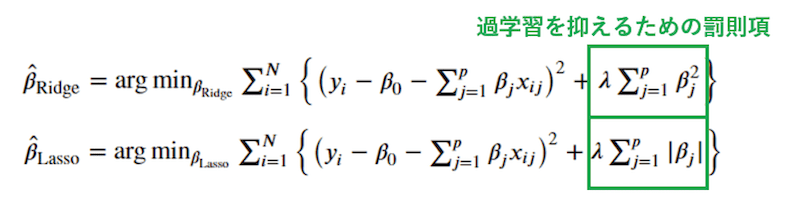
アンサンブル
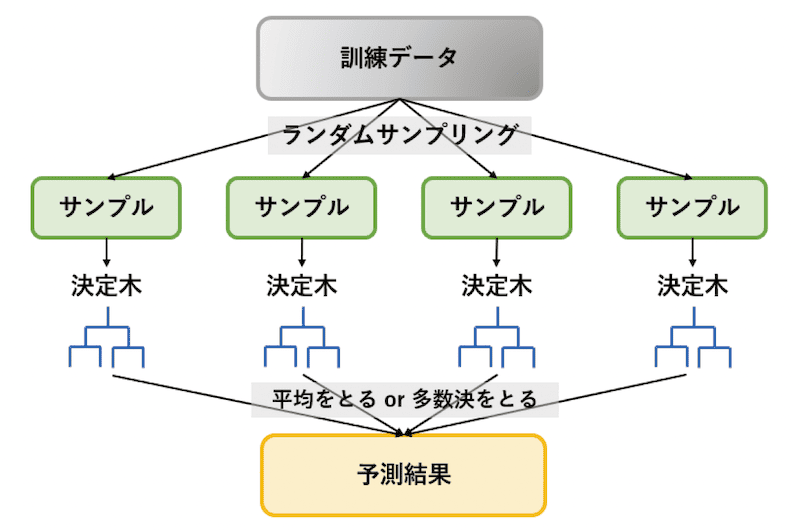
アンサンブルは複数のモデルを組み合わせて最終的な出力の精度を改善する技術です。アンサンブルの代表的な例としてバギングというアンサンブル手法を用いて、複数の決定木を組み合わせるランダルフォレストというモデルがあります。ランダムフォレストは元データと特徴量をランダムサンプリングして、それぞれ異なる方向にオーバーフィッテイングさせた決定木を集め平均や多数決をとり、ノイズの背後にあるデータの傾向や構造を抽出します。
テストデータのオーバーフィッティング
「アセットマネージャーのためのファイナンス機械学習(※2)」によると、オーバーフィッティングには、訓練データのオーバーフィッティングとテストデータのオーバーフィッティングの2種あるといわれています。
訓練データのオーバーフィッティングは、データのノイズを拾って上手く予測できない状態を示します。ここまで説明した特徴量選択、正則化、アンサンブルは訓練データのオーバーフィッティング対策です。しかしノイズは訓練データだけではなくテストデータにも存在します。そのため開発しているうちにテストデータのノイズの影響で上振れしたテスト結果を出し、戦略を過大評価してしまう問題に陥ることがあります。
「ファイナンス機械学習(※3)」ではこのような危険性を考慮したバックテスト手法のCPCVを提案しています。
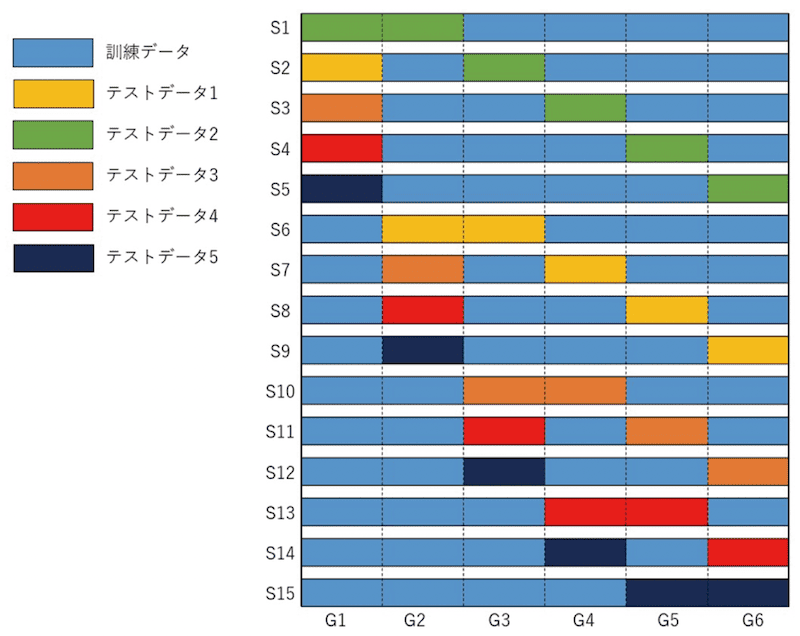
図では5つのテストデータを生成するCPCVを示していますが、実際にはもっと多くのテストデータを生成します。それぞれのテストデータはどの箇所でモデルが学習したのかが違うわけですが、中には偶然上振れするものや偶然下振れするものもあり、それらの分布を調べることで戦略の適切な評価を可能にします。
参考文献
(※1)須山敦志著 (2017). ベイズ推論による機械学習入門, 杉山将監修. 講談社, 機械学習スタートアップシリーズ.
(※2)マルコス・ロペス・デ・プラド著 (2020). アセットマネージャーのためのファイナンス機械学習, 鹿子木 亨紀訳. 一般社団法人金融財政事情研究会.
(※3)マルコス・ロペス・デ・プラド著 (2019). ファイナンス機械学習-金融市場分析を変える機械学習アルゴリズムの理論と実践, 長尾 慎太郎監訳, 鹿子木 亨紀監訳, 大和アセットマネジメント訳. 一般社団法人金融財政事情研究会.
![アイネット証券[アイネットFX]](https://img.tcs-asp.net/imagesender?ac=C118566&lc=INET1&isq=25&psq=2)




![藍崎統計研究所[藍崎@システムトレーダー]](https://forex-online.jp/wp-content/uploads/2024/02/vol8-aisaki-system-trader-1-640x360.png)


![「円ドルチャート」で円高円安を直感的に理解!|TradingView魔改造マニュアル[vol.1]](https://forex-online.jp/wp-content/uploads/2024/08/vol11-tradingview-ozaki-1-640x360.jpg)














![【億トレインタビュー】成功者が多いやり方を選んだ。それがスキャルピングだった[ジュンFXさん]](https://forex-online.jp/wp-content/uploads/2023/03/vol2-jyunfx-1-320x180.jpg)
























